Модель ChatGPT GPT-4o генерирует изображения с читабельными надписями

OpenAI представила важное обновление для GPT-4o, которое позволяет генерировать изображения с невероятно точным текстом. Эта новая возможность позволяет пользователям создавать детальные, высококачественные изображения с помощью языковых подсказок и корректировать их в процессе, чтобы точно воспроизвести задуманное.
Что известно
Похоже, теперь можно забыть о неразборчивых надписях или причудливых символах, которые часто появлялись в старых моделях искусственного интеллекта.
В отличие от традиционных методов генерации изображений, где нужно совершенствовать один запрос, GPT-4o использует динамический подход. Сначала предоставляете основную подсказку, например, "кот", а затем можете вести диалог с моделью, чтобы добавить желаемые детали, например шляпу детектива или монокль.






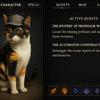

В OpenAI показали, как пользователи могут постепенно создавать сцены, комбинируя элементы из разных изображений. Модель демонстрирует высокую точность в воспроизведении текста на вывесках или предметах, что стало значительным прогрессом по сравнению с предыдущими моделями, которые не могли правильно воспроизводить написанные слова.
GPT-4o также позволяет работать с фотографиями, накладывая на них изменения. Модель справляется с 10-20 объектами в сцене, где другие модели часто останавливаются на 5-8.




Однако не все идеально: существуют некоторые недостатки, такие как обрезание снизу, недоразумения с нелатинским текстом и проблемы при работе с более чем 20 объектами. Но, несмотря на это, новая функция обеспечивает точность и гибкость, которые открывают новые возможности для дизайнеров и творческих людей.
Источник: OpenAI, Gizmochina
Подписывайтесь на наш нескучный канал в Telegram, чтобы ничего не пропустить.