The ChatGPT GPT-4o model generates images with readable labels

OpenAI has introduced an important update to GPT-4o that allows you to generate images with incredibly accurate text. This new capability allows users to create detailed, high-quality images with speech prompts and adjust them in the process to accurately reproduce their intended meaning.
Here's What We Know
It looks like we can now forget about illegible inscriptions or bizarre symbols that often appeared in older AI models.
Unlike traditional image generation methods, where you need to improve a single query, GPT-4o uses a dynamic approach. First, you provide a basic clue, such as "cat", and then you can engage in a dialogue with the model to add desired details, such as a detective's hat or monocle.






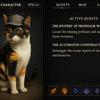

OpenAI showed how users can gradually create scenes by combining elements from different images. The model demonstrates high accuracy in reproducing text on signs or objects, which is a significant advance over previous models that could not correctly reproduce written words.
The GPT-4o also allows you to work with photos by applying changes to them. The model can handle 10-20 objects in a scene, where other models often stop at 5-8.




However, not everything is perfect: there are some drawbacks, such as cropping from the bottom, misunderstandings with non-Latin text, and problems with more than 20 objects. Nevertheless, the new feature provides accuracy and flexibility that open up new possibilities for designers and creatives.
Source: OpenAI, Gizmochina