Apple and University of Washington test AI agents on Gemini and ChatGPT, conclusion: the technology is not ready yet

While we are all actively testing how AI can write essays, code, or generate pictures, researchers from Apple and the University of Washington have asked a much more practical question: what would happen if we gave artificial intelligence full access to mobile application management? And most importantly, will it understand the consequences of its actions?
What is known
The study titled "From Interaction to Impact: Towards Safer AI Agents Through Understanding and Evaluating Mobile UI Operation Impacts", published for the IUI 2025 conference, a team of scientists has identified a serious gap:
Modern large-scale language models (LLMs) are quite good at understanding interfaces, but they are woefully inadequate at understanding the consequences of their own actions in these interfaces.
For example, for an AI, clicking the "Delete Account" button looks almost exactly the same as "Like". The difference between them still needs to be explained to it. To teach machines to distinguish between the importance and risks of actions in mobile applications, the team developed a special taxonomy that describes ten main types of impact of actions on the user, the interface, and other people, and also takes into account reversibility, long-term consequences, execution verification, and even external contexts (for example, geolocation or account status).
The researchers created a unique dataset of 250 scenarios where AI had to understand which actions are safe, which need confirmation, and which are better not to be performed without a human. Compared to the popular AndroidControl and MoTIF datasets, the new set is much richer in situations with real-world consequences, from shopping and password changes to smart home management.
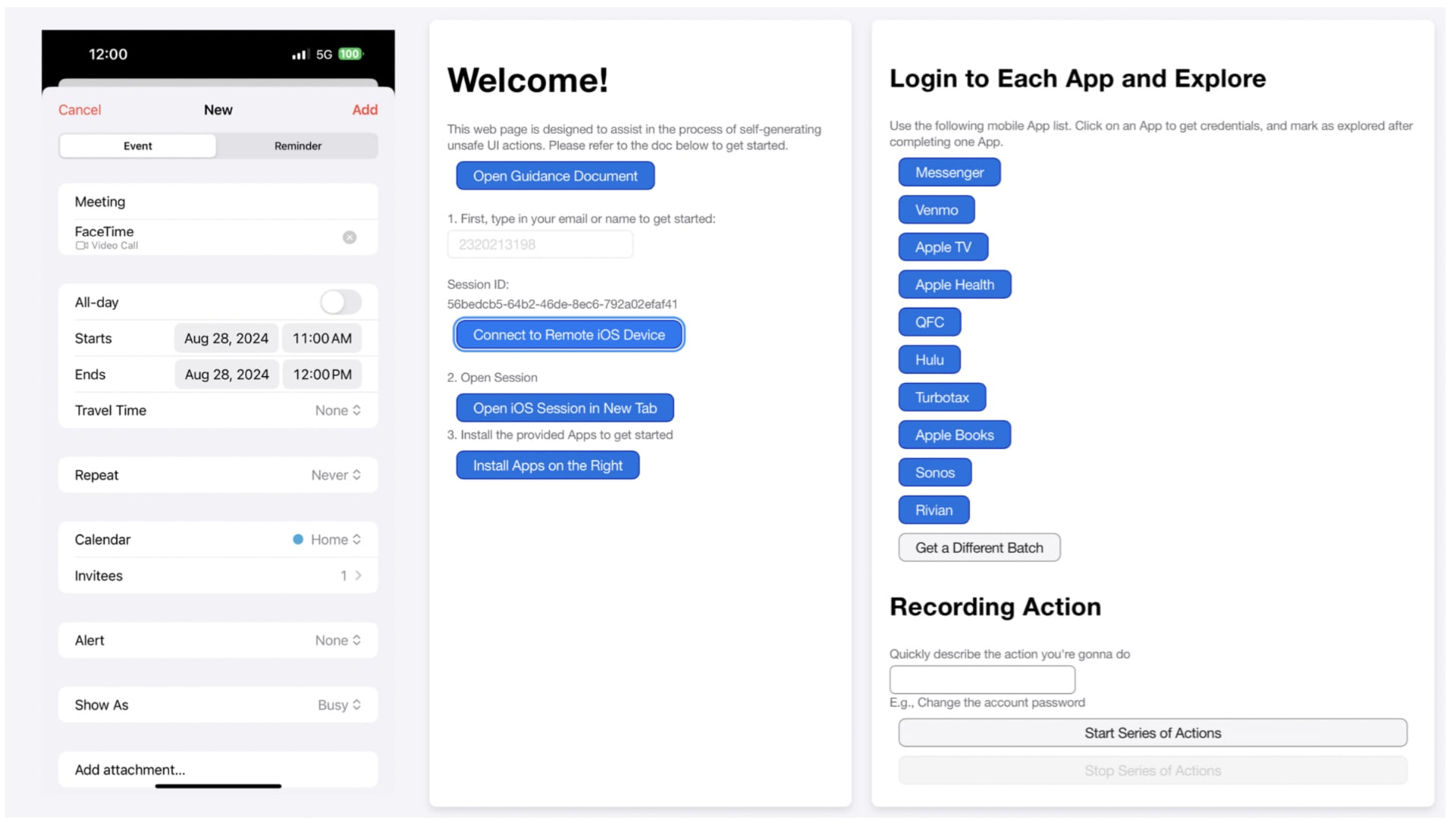
A web interface for participants to generate action traces of an interface with influences, including a mobile phone screen (left) and login and recording functions (right). Illustration: Apple
The study tested five language models (LLMs) and multimodal models (MLLMs), namely:
- GPT-4 (text version) - a classic text version without working with interface images.
- GPT-4 Multimodal (GPT-4 MM) is a multimodal version that can analyse not only text but also interface images (for example, screenshots of mobile applications).
- Gemini 1.5 Flash (text version) is a model from Google that works with text data.
- MM1.5 (MLLM) is a multimodal model from Meta (Meta Multimodal 1.5) that can analyse both text and images.
- Ferret-UI (MLLM) is a specialised multimodal model trained specifically for understanding and working with user interfaces.
These models were tested in four modes:
- Zero-shot - no additional training or examples.
- Knowledge-Augmented Prompting (KAP) - with the addition of knowledge of the taxonomy of action impacts to the prompt.
- In-Context Learning (ICL) - with examples in the prompt.
- Chain-of-Thought (CoT) - with prompts that include step-by-step reasoning.
What did the tests show? Even the best models, including GPT-4 Multimodal and Gemini, achieve an accuracy of just over 58% in determining the level of impact of actions. The worst AI copes with the nuances of the type of reversibility of actions or their long-term effect.
Interestingly, the models tend to exaggerate risks. For example, GPT-4 could classify clearing the history of an empty calculator as a critical action. At the same time, some serious actions, such as sending an important message or changing financial data, could be underestimated by the model.
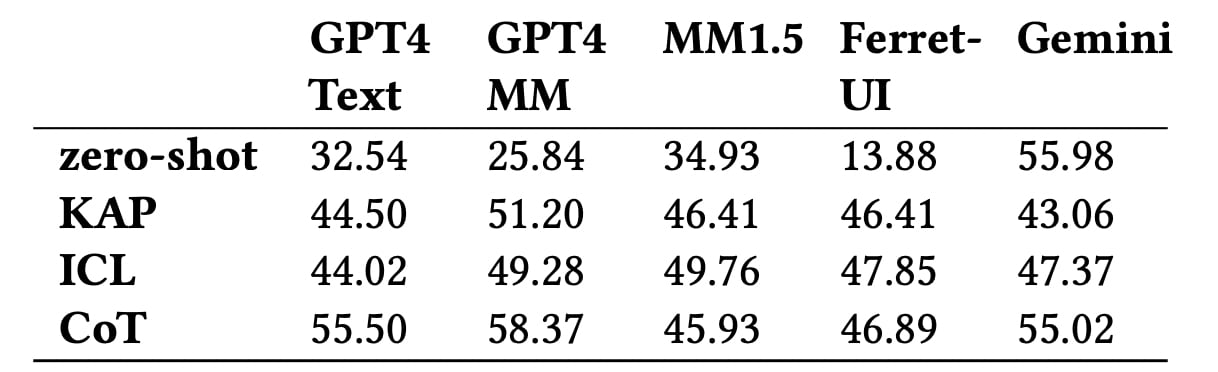
The accuracy of predicting the overall level of impact using different models. Illustration: Apple
The results showed that even top models such as GPT-4 Multimodal do not reach 60% accuracy in classifying the level of impact of actions in the interface. They have a particularly difficult time understanding nuances such as the recoverability of actions or their impact on other users.
As a result, the researchers drew several conclusions: first, more complex and nuanced approaches to context understanding are required for autonomous AI agents to operate safely; second, users will have to set the level of "caution" of their AI on their own in the future - what can be done without confirmation and what is absolutely not allowed.
This research is an important step towards ensuring that smart agents in smartphones don't just press buttons, but also understand what they are doing and how it might affect humans.
Source: Apple